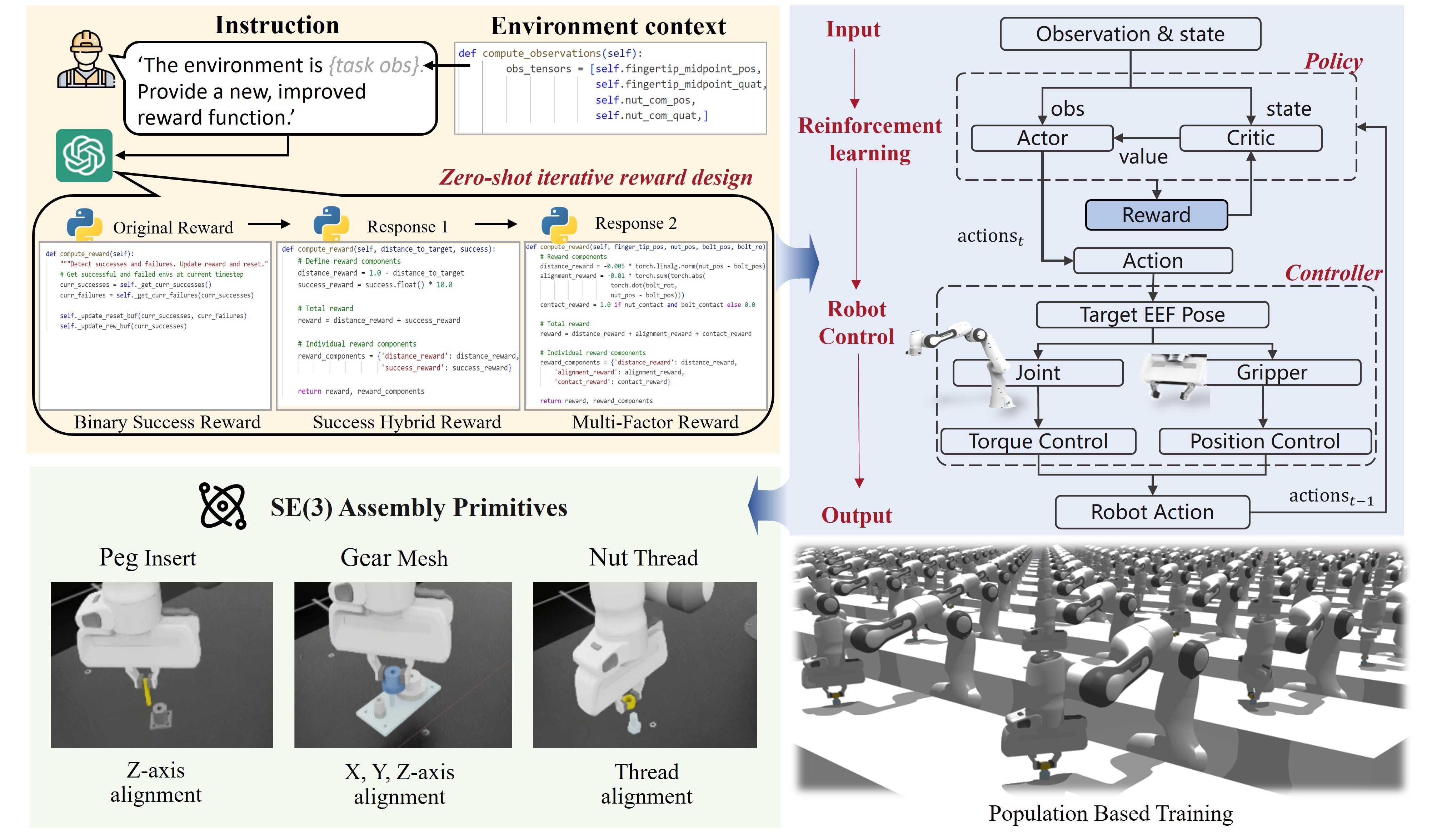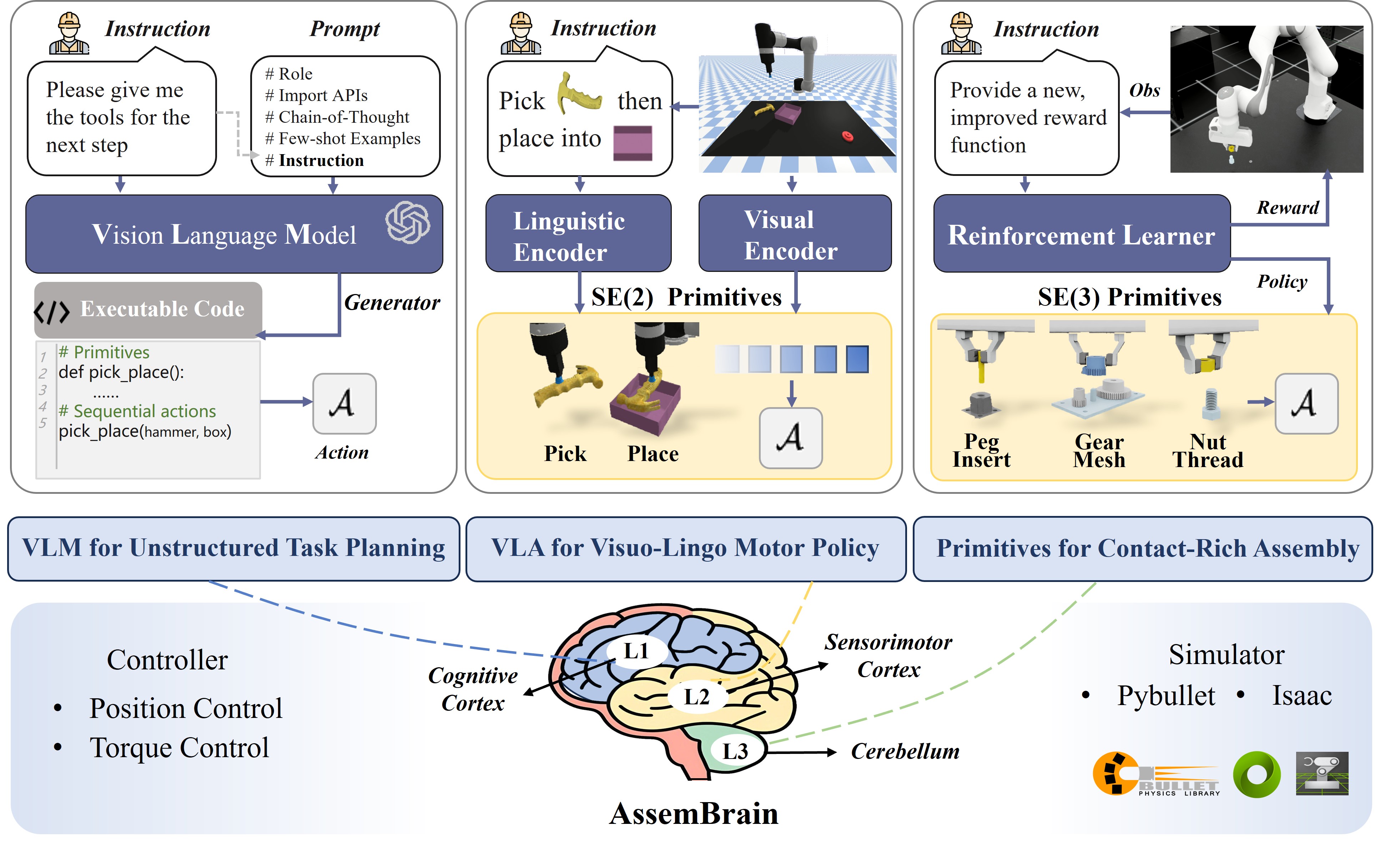
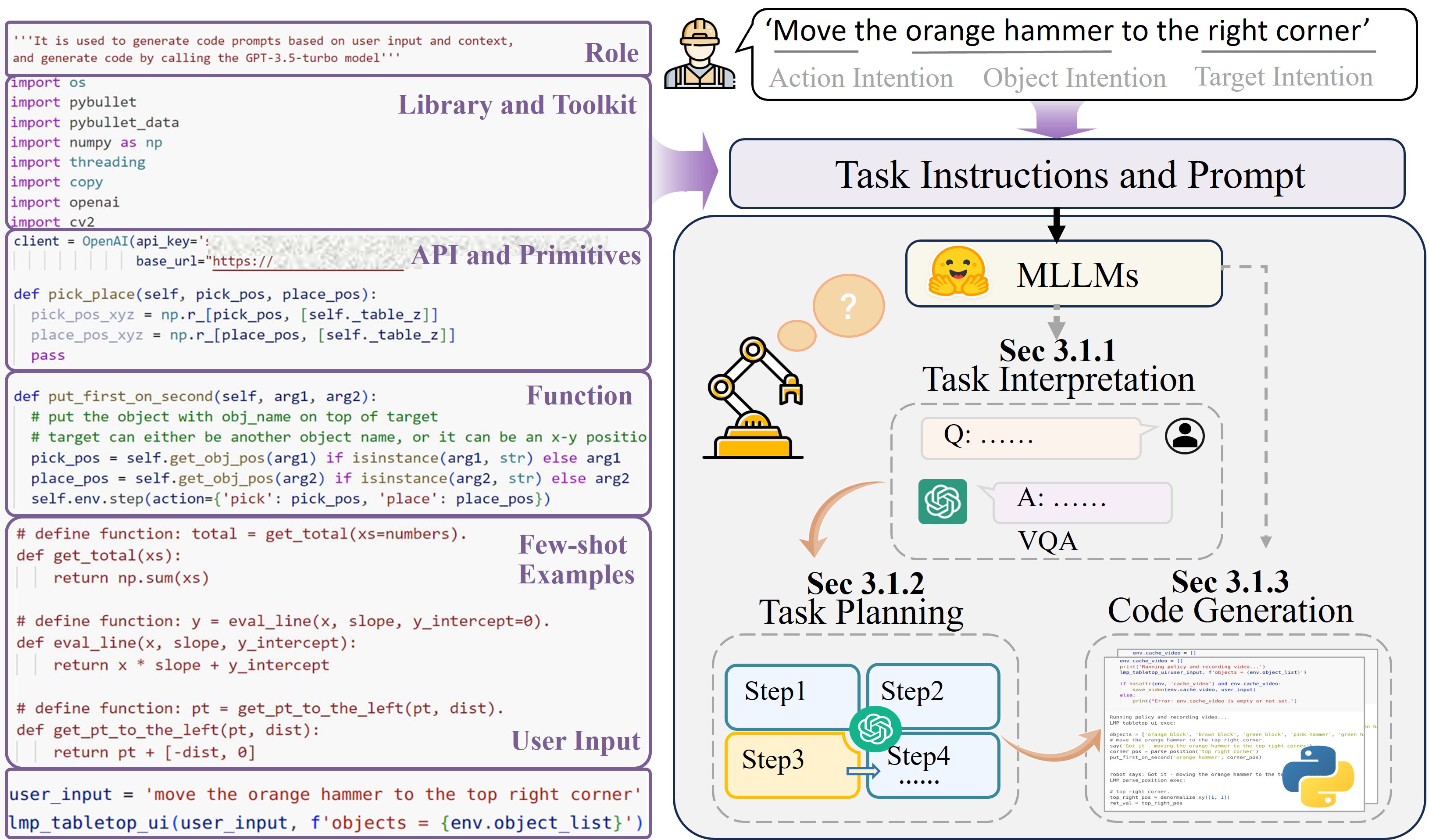
1. LLM for Unstructured Task Planning
Level 1 (L1): "Cognitive Cortex"
L1 corresponds to the brain's higher-order cognitive regions,
focusing on understanding language instructions and long-term planning.
This is fulfilled by MLLMs, which support zero-shot task interpretation,
code generation, and task decomposition for unstructured tasks.
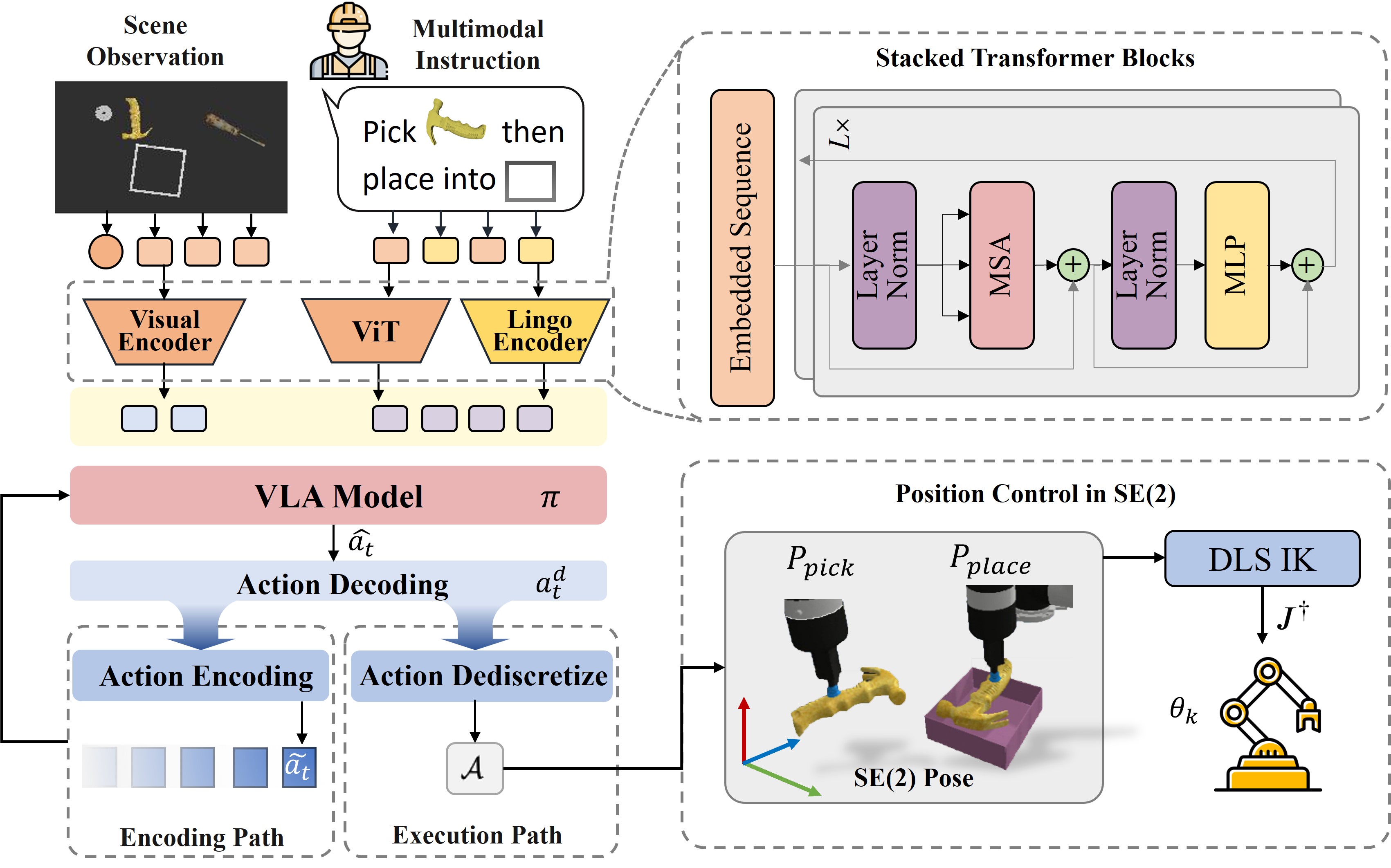
2. VLA for Visuo-Lingo Motor Policy
Level 2 (L2): "Sensorimotor Cortex"
L2 mirrors the sensorimotor regions that integrate visual and linguistic
inputs to guide physical actions.
This is embodied by Vision-Language Action models,
excelling in SE(2) planar tasks such as pick-and-place.
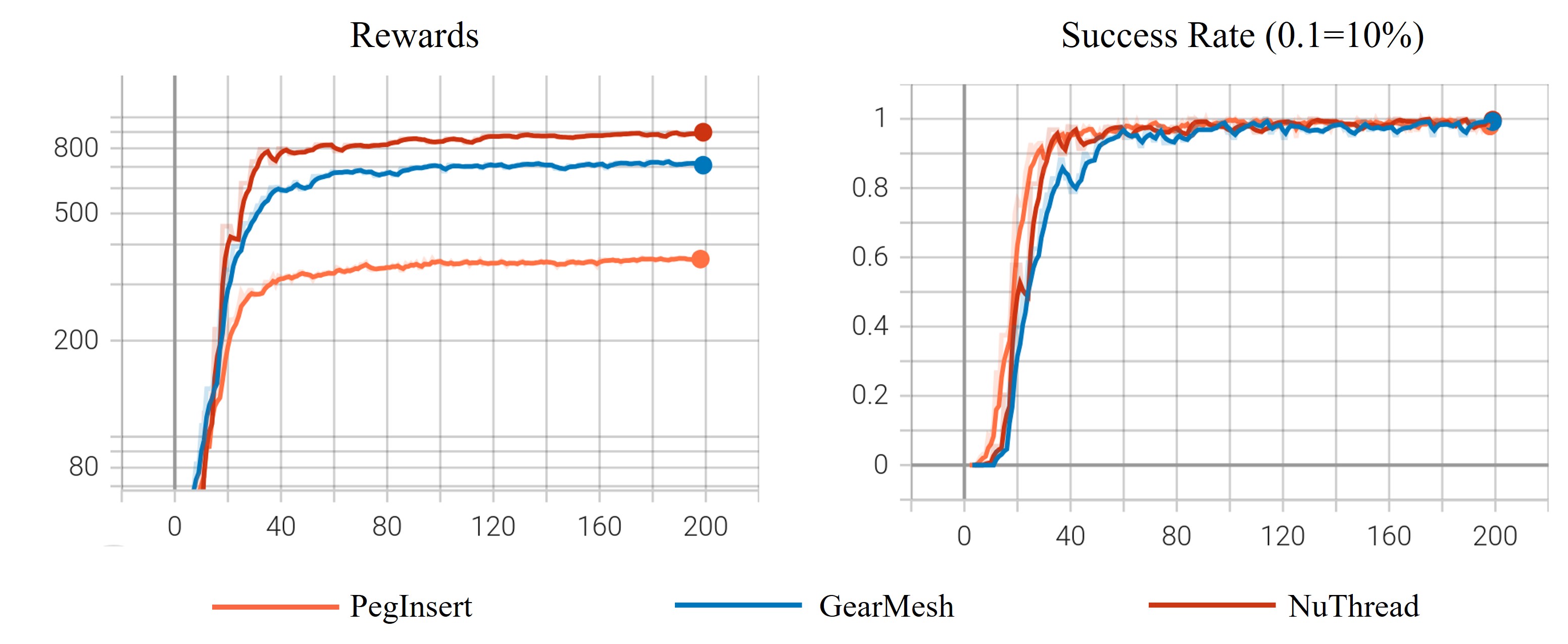
3. Primitives for Contact-Rich Assembly
Level 3 (L3): "Cerebellum"
L3 is like the cerebellum, which refines motor commands for precision and stability.
This paradigm leverages action primitives and reinforcement learning
to execute complex SE(3) manipulation in contact-rich assembly,
handling the nuances of force control and adaptation.